首先
终于完整地读完第一篇论文了!
师兄关于抠图的论文《Pixel-level Discrete Multiobjective Sampling for Image Matting》。
师兄超Nice的,被无知的我穷追不舍(师兄好可怜),但我还是只能稍作了解。
现记录如下,有理解错误和不足的地方会及时改正。:)
关于抠图
「抠图」的主要任务很简单,就是从一张图片中,把你需要的物体(前景)从图像中提取出来。其操作是通过评估每个像素点的透明度来完成的。
Image matting refers to the soft extraction of foreground objects from a color image by estimating the opacity of each pixel.
抠图方法
一个重要公式
I 为该像素由我们肉眼观察到的颜色
F 为该像素对应的前景的颜色
B 为该像素对应的背景的颜色
i 表示通道,比如在RGB色域中就是R G B三个通道啦
其实就是一个颜色叠加,用 α 和 1-α 来表示前景/背景的透明度
抠图所需内容
所需内容有 2 张图片:
- 一张待抠图片(当然)
- 一张大致确定前景/背景位置的图片(Trimap or Scribble)
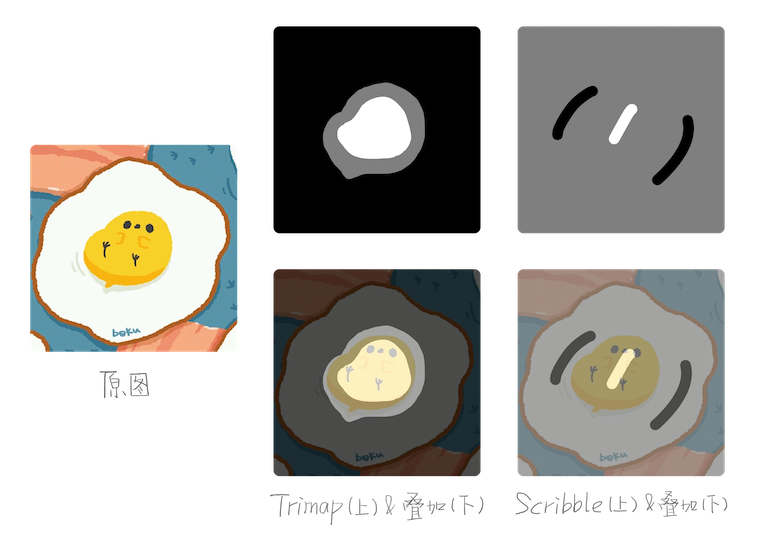
Trimap & Scribble
对于第 2 个,可能会比较陌生,但看下图就好理解了。其实就是一个用来划分区域的「三色图」。
「黑色区域」表示确定为「背景」的区域;
「白色区域」表示确定为「前景」的区域;
「灰色区域」表示「不确定」的区域。
而抠图算法的最终目的,就是消除这个不确定的区域。
有「trimap」和「scribble」两种,trimap 比较精准,而 scribble 就是用户手画的随便指定了一下前景和背景区域。
当然后者更便于用户使用,但确定的区域少了,难度也随之增加了。
抠图的产物
这还用说吗!当然是抠出来的图啊!
注意了(敲黑板)!这里可能会有人和我一样进入一个误区,认为抠图的最终产物是一张前景图。
其实不是的,抠图的产物是一个叫做「Alpha mattes」的东西,如下图所示。

就是一个蒙版,每个像素的灰度值代表透明度。
「黑色」代表该像素透明度为 0;
「白色」代卖该像素透明度为 1;
「灰色」按照灰度确定该像素的透明度。
有了这个 Alpha mattes 我们就已经把前景给提取出来了。
至于所说的前景图,师兄说那是「图像合成」的事了。
而且,如果用于图像合成的话,不仅仅需要生成一个 Alpha mattes 还需要一个「F」,即一个前景色的图!
为什么呢?我放在最后「思考」中介绍吧,一直扩展还下不下课了!喂喂!
现有方法
现主要抠图算法都基于以下 3 种方法:
- 基于采样算法 Sampling-Based
- 基于遗传算法 Propagation-Based
- 以上两者混合 Hybrid Methods
该论文的做法是基于采样的,所以比较详细说明了采样。
其他两种我的脑子告诉我它不会,等我喂饱它之后再来补充。
基于采样方法
基于采样的方法又分为了「参数型 Parametric」和「无参型 Non-Parametric」两种。
先说结论,该论文用的是「无参型」。
Parametric
和该论文实现无关,贴上原文观摩观摩就好啦。
In parametric methods, pixel colors are assumed to obey a specific distribution, and the distribution parameters are estimated from the pixels in known regions. Alpha values are estimated according to the distance between the color of the unknown pixel and the color distribution of known regions.
Non-Parametric
这方法就是说呢,从之前的「Trimap」或「Scribble」里得到已知的「前景区域」和「背景区域」。
对于某一未知区域的像素点,从以上两个确定区域中选取一对像素作为样本,即得到了 B 和 F ,再加上该未知区域像素的 I 就可以通过上面的「重要公式」求出 α 了。
最后判断这个 α 是否符合标准就好(什么标准啊,你话不要说一半啊!)。
In non-parametric methods, foreground and background color samples are obtained from known regions, whereby an objective function is used to find an optimal pair of foreground and background samples.
计算 α 的公式
该公式是由以上「重要公式」推导出来的,有多个颜色通道,所以这里的 I、F、B 均为向量。
其中 ‖*‖₂ 为欧几里德范数,在这里就和「模」差不多。
推导过程在「思考」部分,这里和后面的内容有关联,是我之前困惑的地方,所以想着重说明一下。
流程

1. Pre-Processing
预处理阶段,主要是通过一些算法来缩小「Trimap」或「Scribble」中「未知区域」的空间,减少之后的计算量。比如使用一些颜色相近和空间相近原则,来扩张已确定的「前景区域」和「背景区域」。
2. Color Sampling
前景色和背景色的取样阶段。第二个公式中的 F 和 B 并不是大海捞针,每一个都测试一遍的。而是从一堆可行解里面选择,这堆可行解就是通过「Color Sampling」过程筛选出来的。
这个阶段就是本文重点优化的阶段。
3. Sample Pair Selection
从上一个步骤中根据目标函数选取最佳的样本,也就是公式中的 F 和 B 了。
4. Solving Alpha
将上一步得到的 F 和 B 带入第二个公式求出 α ,从而得到「Alpha mattes」。
5. Post-Processing
后处理阶段,通过一些算法使得「Alpha mattes」的图像更加平滑。
现有方法的不足之处
不足之处主要在于「Color Sampling」阶段。如上面所说抠图主要运用「第二个公式」的 F 和 B 求出 α 进而得到最终产物「Alpha mattes」,F 和 B 都要从候选样本中选取,所以该阶段是整个抠图过程的关键。
Color Sampling 的困难点
「Color Sampling」阶段的困难主要在于两点,「取样标准选取」和「取样集合太大」的问题。
已有的解决方法
对于「取样标准选取」的解决方法,最早提出的是一种「基于距离的取样方法」,即样本应该离未知点越近越好,这样的话选取的样本一般都集中在未知点到已知区域的边界处。但是很遗憾,通常正确的样本并不一定离未知点很近,所以需要多种标准来选择,比如「距离」、「颜色」、「纹理」等。所以提出了「基于多种标准的取样方法」
对于「取样集合太大」的解决方法,通常采用叫做「Superpixels」的方法。简单来说就是把很多颜色相近的像素点聚集起来成为一个「超像素」,这个「超像素」中只有一个颜色,就是之前聚集的像素点的「颜色均值」。这样就大大减少了取样集合的大小。
不足之处
对于「基于多种标准的取样方法」来说,主要的问题在于「多种标准之间的冲突问题」,如一个正确的样本,它的颜色和未知点很近,但是距离却和未知点很远,这样标准之间就产生了冲突,很可能将正确的点给抛弃掉。从而产生「丢失正确样本 Missing True Samples(MTS)」的问题。
For example, if true color samples sembled to the color of an unknown pixel are far from the unknown pixel, the spatial closeness criterion and color criterion will be in conflict. The true samples may not be collected by existing methods in this case, because the dissatisfaction of spatial closeness criterion may result in uncompetitive scores for the true samples in the comparison to that for the pixels closed to unknown pixels.
对于「Superpixels」来说,也一样的,可能正确的样本颜色被均值化,从而产生「MTS」问题。
The mean color of a superpixel cannot represent the color outliers in the superpixel which may be the true color sample for alpha estimation.
改进方法
该论文提出的「Pixel-level Discrete Multiobjective Sampling(PDMS)」算法主要就是为了避免「MTS」问题。
多目标优化
对于「多种标准之间的冲突问题」,将其看做「多目标优化问题 Multiobjective Optimization Problem (MOP)」,从而解决标准之间的冲突。目标函数如下:
其中\(g_{1}(x)\)、\(g_{2}(x)\)、\(g_{3}(x)\)为三个目标函数
\(x\)为已知区域中的某个点,\(z\)为当前计算的未知区域点
\(C\)为颜色向量、\(S\)为空间坐标向量、\(T\)为纹理特征向量
同时使所有目标函数最小化
注意这里只是一个样本点的选取,在「Color Sampling」过程中是要选取 F 和 B 两个样本点的,所以该问题其实是两个「MOP」问题。
Pixel-Level
对于「Superpixels」的问题,想法很简单,既然均值化会丢失真实样本,那不均值化好了,直接从所有像素中取样,即「Pixel-Level」。但「取样集合太大」的问题不又回来了吗,进入死循环中。
这个时候就需要跳出固定思维了,本文通过设计了一个新的算法「Fast Discrete Multiobjective Optimization(FDMO)」从而避免了「取样集合太大」导致的「计算量过大问题」。
FDMO
「FDMO」的主要优化依据在于,经过「MOP」筛选之后,候选样本集所在的「Pareto Optimal Solution」很小很小。在 168,409 个可行解中最后只有 11 在「Pareto Set」中。
For the foreground sampling MOP defined in Subsection III-A2, the universal set contains 168,409 feasible solutions while only 11 solutions are Pareto optimal in this case.
在这样的情况下,算法的核心思想就是在每一趟遍历中,把所有该剔除(被支配)的样本给剔除掉。这样如果最终「Pareto Optimal Solution」的大小为 k,就只需要在 k 趟遍历中完成算法。设取样集合总大小为 n 则算法的时间复杂度为 O(kn) 。
/*
* Input: all possible values C.
* Output: C, i (the first i − 1 elements in array C are Pareto optimal)
*/
i ← 1
j ← the number of elements in array C
while i ≤ j do
cmp ← i + 1
while cmp ≤ j do
if C[i] dominate C[cmp] then
swap(C[cmp], C[j])
j ← j − 1
else if C[cmp] dominate C[i] then
swap(C[i], C[cmp])
swap(C[cmp], C[j])
j ← j − 1
cmp ← i + 1
else
cmp ← cmp + 1
end if
end while
i ← i + 1
end while
return C, i
| Best | Worst | Average | |
|---|---|---|---|
| 时间复杂度 | \(O(n)\) | \(O(n^2)\) | \(O(kn)\) |
| 空间复杂度 | \(O(n)\) | \(O(n)\) | \(O(n)\) |
选取样本对的方法
也就是「Sample Pair Selection」阶段,在上一阶段中得到的候选样本里选取最佳样本。
其评价方程如下:
是不是头都要炸了?哈哈哈
静下心来,其实很简单
第二个公式的意思就是用算出来的 alpha、B 和 F
反过来求 I’ ,看看这个 I’ 的颜色有多大变化,变化越小越好
第三个公式的意思就是 F 和 B 应该是所有样本里距离最近的
第一个公式就是这两者的叉乘,两者一起评估
结论 & 思考
结论就是该算法最终在「很少的候选样本」中达到了「很小的 Alpha 误差」。
但是速度方面不尽人意,空间方面耗费很小。
思考主要想说一下自己之前对「最终产物」的误解,以及「前景图」生成过程。
还有「第二个公式」的推导过程(因为论文中少了一个平方,困扰了我很久),以及选择样本对时「目标函数」的作用。
最后是「FDMO」算法在我想的一个特殊情况下时间复杂度达到了\(O(2^n)\),以及我的改进方法。
由于篇幅太长了,我自己都不愿看了,这些内容就放到下一篇吧(让我偷个懒)。